
MiMo-Audio: 100M-Hour Pretrained Model for Few-Shot Speech Tasks
MiMo-Audio is a large-scale audio language model pretrained on more than 100 million hours of data. It is designed to generalize from just a few examples or simple instructions to navigate new audio tasks. This adaptability is driven by the MiMo-Audio-Tokenizer—a compact architecture that integrates a patch encoder, a large language model (LLM) backbone, and a patch decoder. This configuration efficiently manages high-rate audio sequences and bridges the length disparity between speech and text.
The MiMo-Audio-7B-Base model establishes a new benchmark for open-source speech intelligence and audio understanding. It successfully performs tasks not explicitly covered in its training data—including voice conversion, style transfer, and speech editing—while producing remarkably natural spoken output. The instruction-tuned variant, MiMo-Audio-7B-Instruct, further enhances these capabilities, matching or surpassing proprietary models in audio comprehension, spoken dialogue, and instruction-driven text-to-speech. Additionally, a built-in reasoning mechanism improves both the model's understanding and its generative accuracy.
Scaling pretraining data beyond 100 million hours gives MiMo-Audio robust few-shot capabilities. Evaluations confirm state-of-the-art results for open models across both speech intelligence and general audio benchmarks. Beyond its core training, the model handles voice conversion, style shifts, and precise editing. Its continuation skills are equally potent, allowing it to generate realistic talk shows, narrations, live streams, and debate clips.
MiMo-Audio-Tokenizer
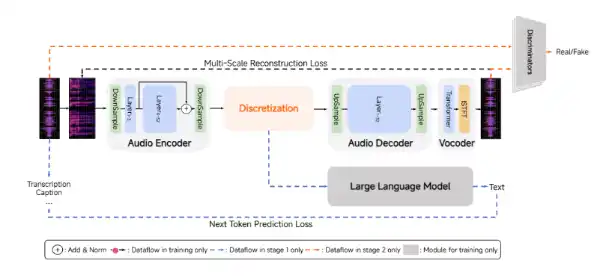
The MiMo-Audio-Tokenizer is a 1.2-billion-parameter Transformer operating at 25 Hz. It utilizes an 8-layer residual vector quantization (RVQ) stack to produce 200 tokens per second. Trained from scratch on 10 million hours of audio, the tokenizer is optimized for both semantic representation and reconstruction fidelity. This results in cleaner audio reconstruction, which significantly simplifies downstream language modeling.
Core Architecture
MiMo-Audio utilizes a patch encoder, an LLM, and a patch decoder. This setup models high-rate sequences efficiently while resolving the inherent length mismatch between speech and text. The patch encoder compresses four consecutive RVQ time steps into a single patch, effectively downsampling the sequence to 6.25 Hz before it reaches the LLM. The patch decoder then employs a delayed generation scheme to autoregressively restore the full 25 Hz RVQ token stream.
Model Downloads
The models are available on Hugging Face.
| Model Name | Hugging Face Repo |
|---|---|
| MiMo-Audio-Tokenizer | XiaomiMiMo/MiMo-Audio-Tokenizer |
| MiMo-Audio-7B-Base | XiaomiMiMo/MiMo-Audio-7B-Base |
| MiMo-Audio-7B-Instruct | XiaomiMiMo/MiMo-Audio-7B-Instruct |
First, install the huggingface-hub package:
pip install huggingface-hub
hf download XiaomiMiMo/MiMo-Audio-Tokenizer --local-dir ./models/MiMo-Audio-Tokenizer
hf download XiaomiMiMo/MiMo-Audio-7B-Base --local-dir ./models/MiMo-Audio-7B-Base
hf download XiaomiMiMo/MiMo-Audio-7B-Instruct --local-dir ./models/MiMo-Audio-7B-Instruct
Environment Setup (Linux)
- Python: 3.12
- CUDA: ≥ 12.0
Installation Steps
- Clone the repository:
git clone https://github.com/XiaomiMiMo/MiMo-Audio.git - Enter the directory:
cd MiMo-Audio - Install dependencies:
pip install -r requirements.txt - Install flash-attn:
pip install flash-attn==2.7.4.post1
If compiling flash-attn takes too long, you can use a pre-built wheel:
- Download the appropriate wheel file.
- Run:
pip install /path/to/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl
MiMo-Audio supports several operational modes: audio understanding, text-to-speech, spoken dialogue, speech-to-text conversation, and text-to-text chat. To begin, set the model and tokenizer paths in the interface (leave them blank for defaults) and click "Initialize Model." The interface will display device information and GPU availability. Once the paths for MiMo-Audio-Tokenizer and MiMo-Audio-7B-Instruct are configured, all features will be accessible.
Inference Scripts
- Base model: Run
inference_example_pretrain.pyto explore the in-context learning capabilities ofMiMo-Audio-7B-Base. - Instruct model: Use
inference_example_sft.pyto test the instruction-tunedMiMo-Audio-7B-Instructvariant.